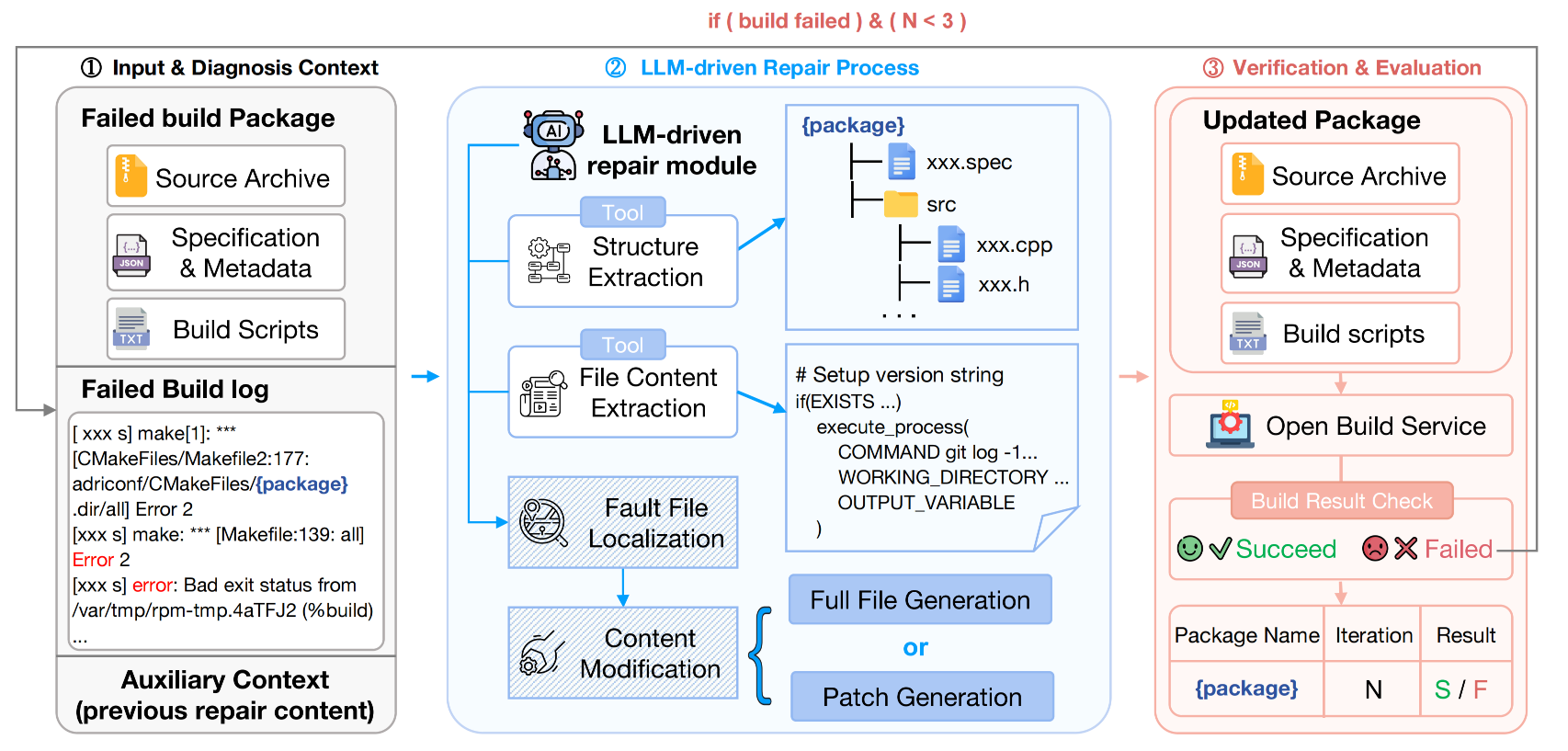
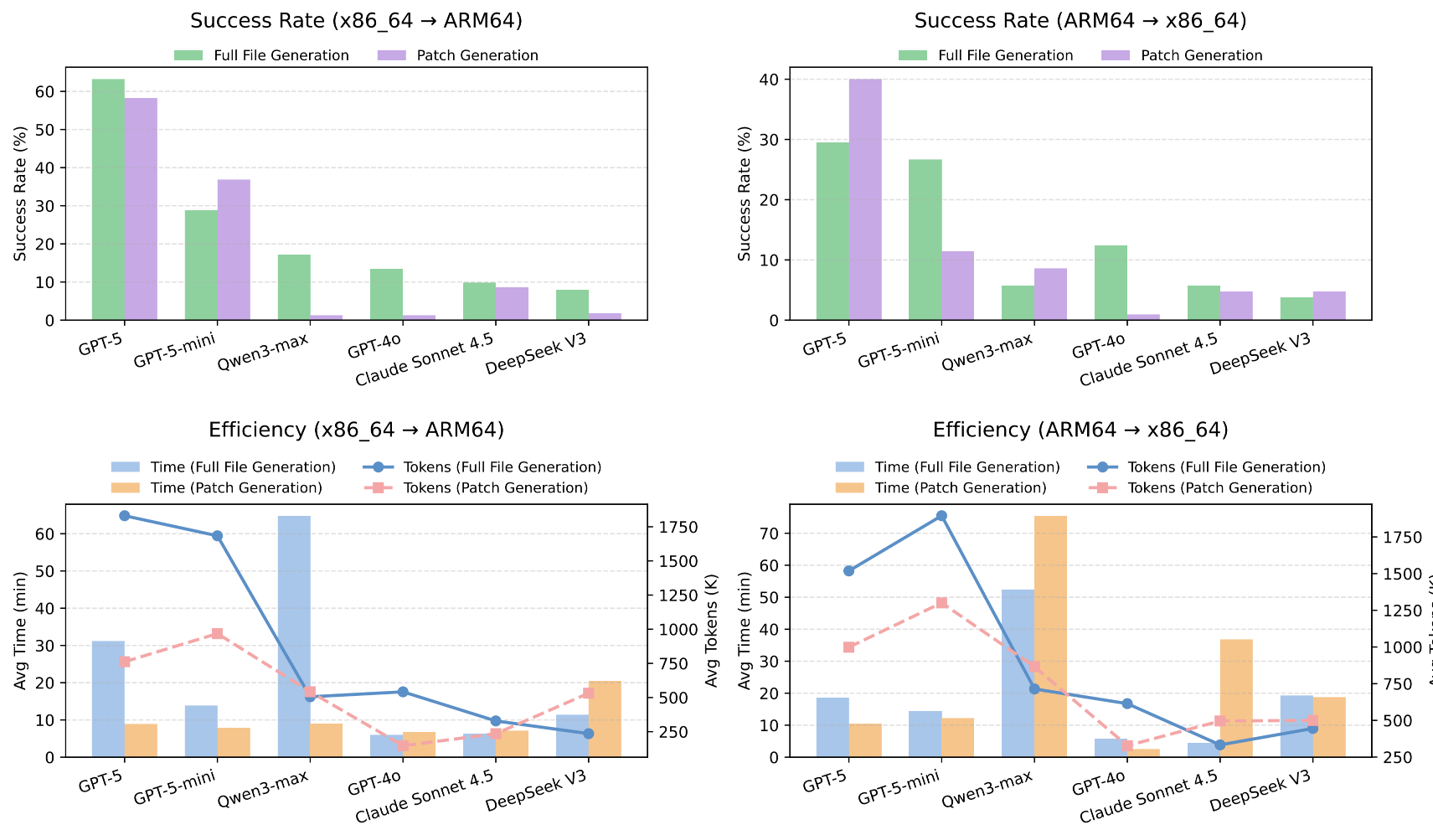
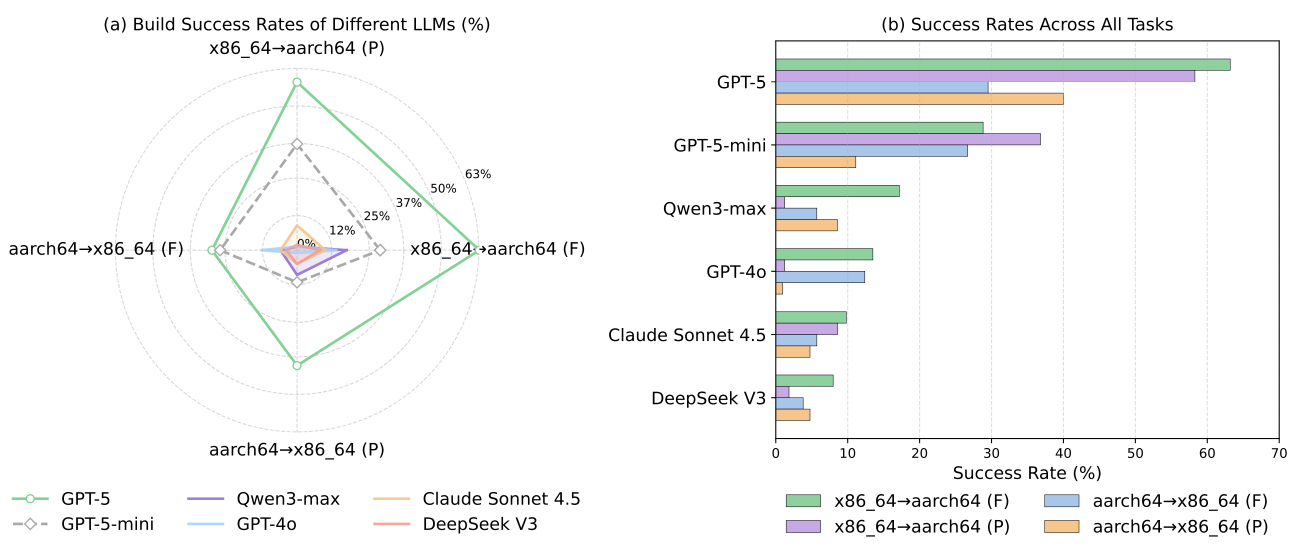
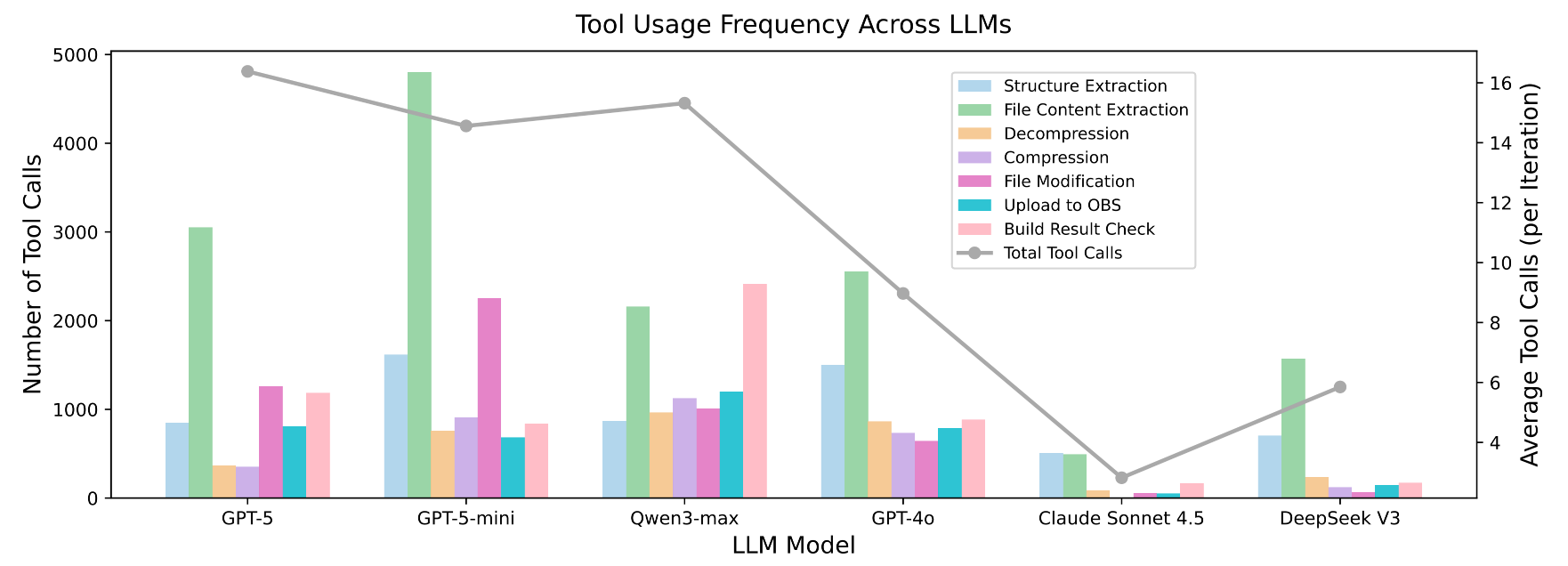
Most software-engineering benchmarks evaluate source-level coding, issue resolution, or test-passing behavior in homogeneous environments. Build-bench targets a different capability: repairing software packages whose build breaks when migrating across instruction set architectures.
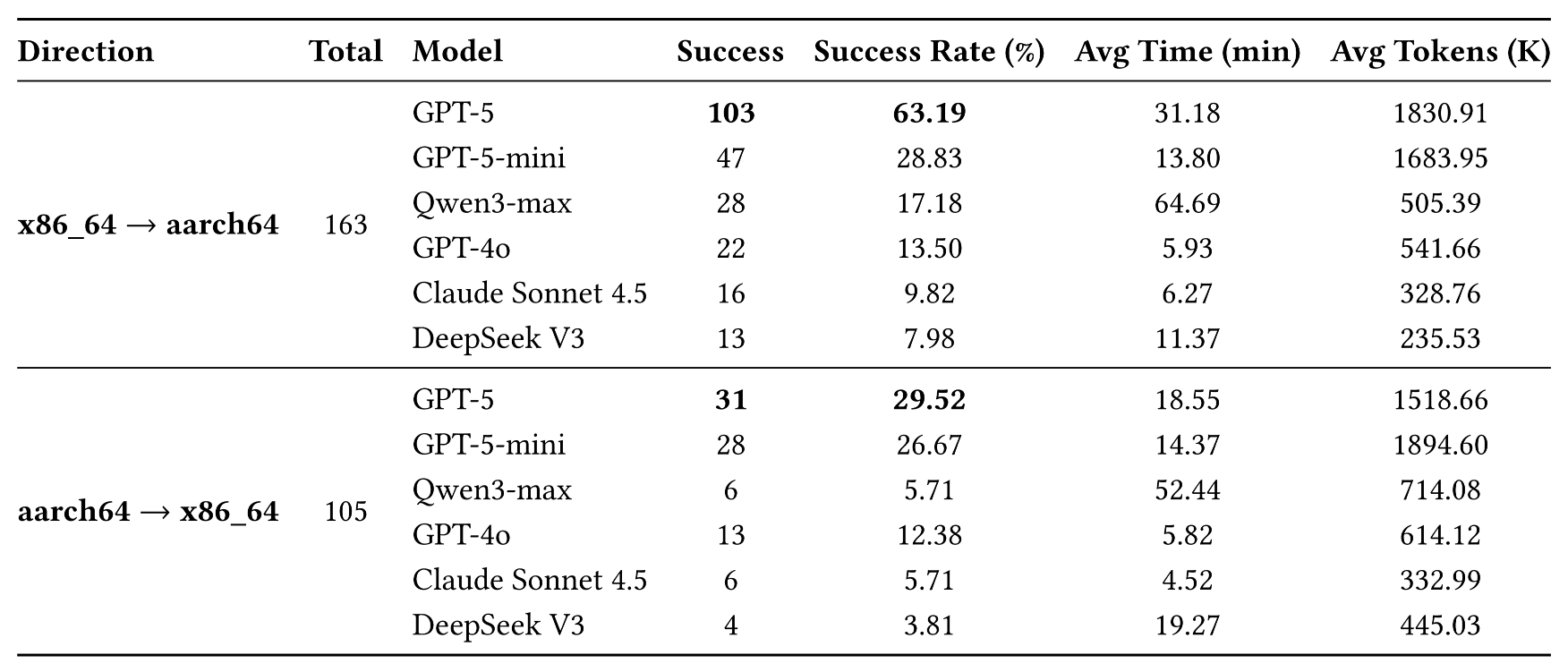
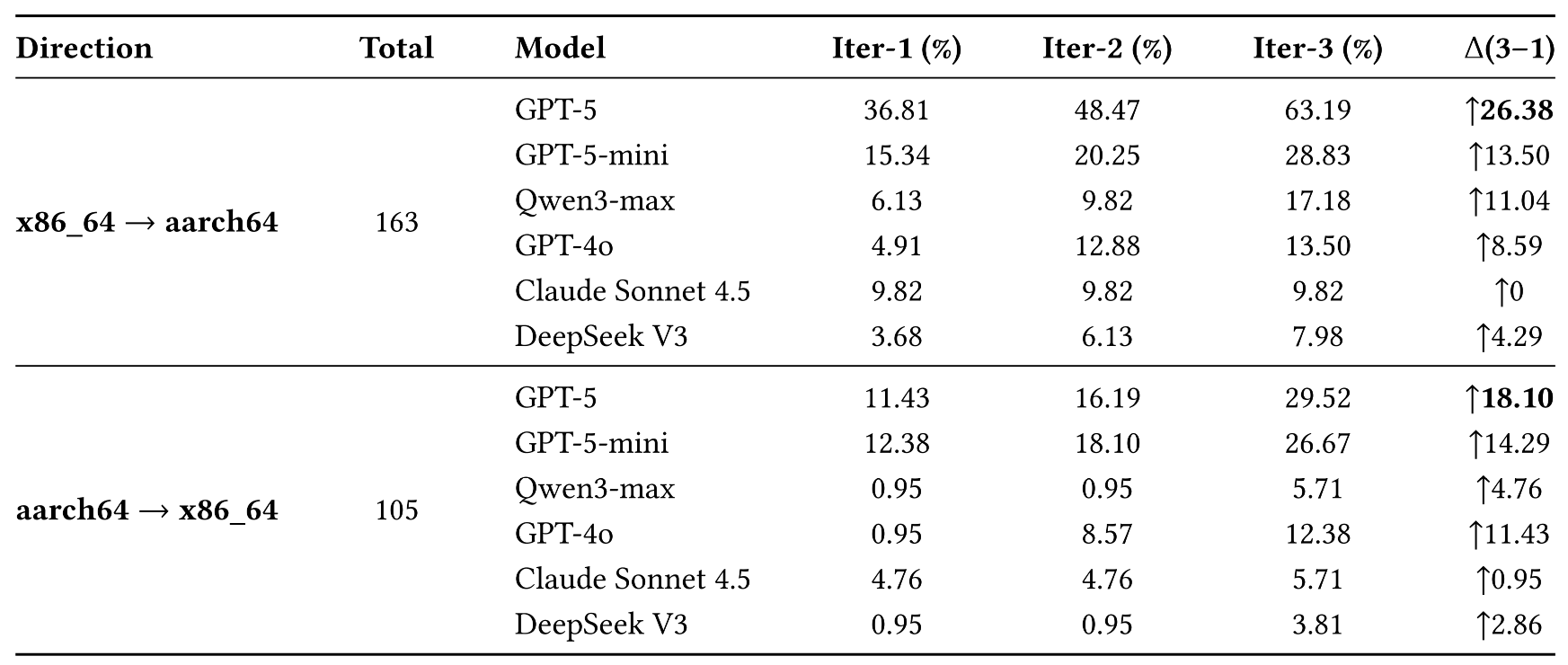
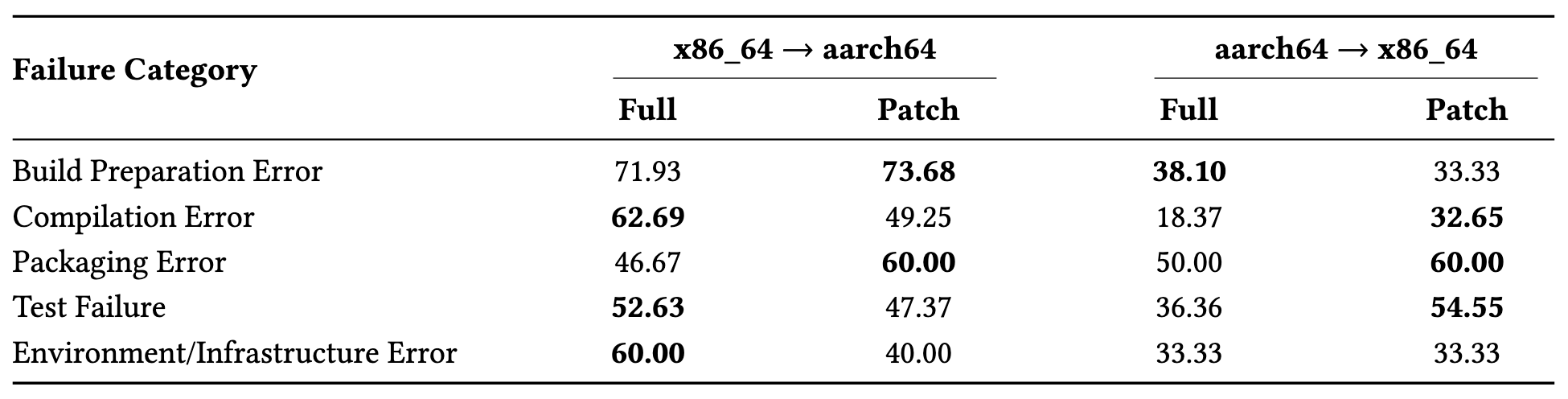
Each task starts from a package that builds successfully on a source architecture but fails on the target architecture. The agent must inspect the package, localize the build failure, modify code or configuration files, upload the repaired package to Open Build Service, and use the executable build result as feedback.
A repair is counted as successful only when the package rebuilds successfully on the target architecture.
268reproducible failed packages
163x86_64 → aarch64 failures
105aarch64 → x86_64 failures
95.90%LLM-assisted labels matching human consensus